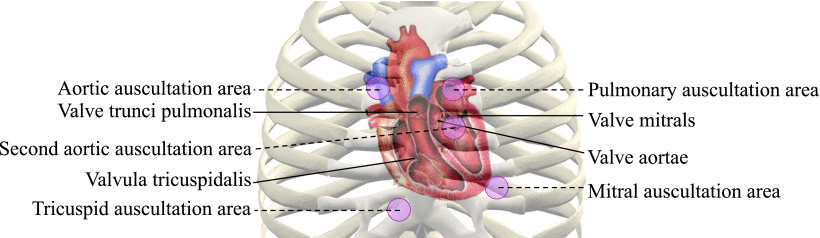
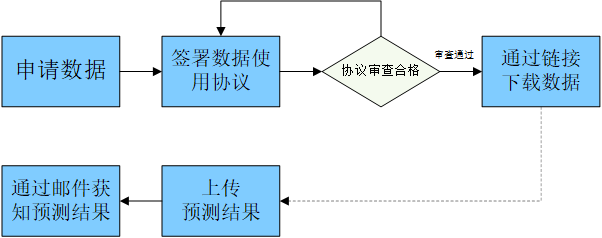
深圳心音数据库 数据库介绍 Heart Sounds Shenzhen Corpus (HSS) 是由深圳大学总医院录制的全新心音数据库,这是迄今为止公开的单一医学中心收集和标注的最大的心音数据库。HSS中的心音数据通过使用蓝牙4.0的电子听诊器(Eko CORE,美国)以4 kHz采样率采集,采集位置为二尖瓣听诊、主动脉瓣听诊、肺动脉瓣听诊和三尖瓣听诊区。对于每个区域,采集受试者坐姿或者仰卧位的心音数据30秒。 心音数据采集位置 HSS数据集共招募到170名患有各种健康状况,包括冠心病、心力衰竭、心律失常、高血压、甲状腺功能亢进、瓣膜性心脏病和先天性心脏病等的受试者。其中女性55名,男性115名,年龄范围为21至88岁(65.4±13.2岁)。样本时长范围为29.808至30.152秒,170名受试者共录得845条样本,共计422.82分钟。 数据标签由经验丰富的心脏病专家使用黄金标准,即超声心动图进行注释。超声心动图使用二尖瓣和三尖瓣面积比预测反流:轻度(小于30%)、中度(30%-50%)、重度(大于50%)。相应地,HSS中心音分为三类:正常、轻度和中度/重度。 作为标准化数据库,HSS 从数据采集、标注,到后期归一化处理和划分都严格按 INTERSPEECH ComParE 挑战赛的规定进行。心音数据的采集工作和处理得到了深圳大学总医院伦理委员会的批准。 所有数据分为训练、开发和测试集,考虑到受试者独立性,在划分数据时,每个志愿者的心音数据只出现在一个数据集中。训练集包含100名受试者的502个样本以及标签,开发集包含35名受试者的180个样本以及标签,测试集仅包含35个受试者的163个样本。 数据获取流程 数据获取流程 模型评估 使用下面的连接来评价你的模型,结果将以邮件形式告知。评估您的预测模型 相关文献 Dong, F., Qian, K., Ren, Z., Baird, A., Li, X., Dai, Z., Dong, B., Metze, F., Yamamoto, Y. and Schuller, B.W., 2019. Machine Listening for Heart Status Monitoring: Introducing and Benchmarking HSS—The Heart Sounds Shenzhen Corpus. IEEE Journal of Biomedical and Health Informatics, 24(7), pp.2082-2092. 使用HSS的文章 Ren, Z., Qian, K., Dong, F., Dai, Z., Nejdl, W., Yamamoto, Y. and Schuller, B.W. 2022. Deep Attention-based Neural Networks for Explainable Heart Sound Classification. Machine Learning with Applications, 9, p.100322. doi:10.1016/j.mlwa.2022.100322.Ren, Z. 2022. Deep Learning Techniques for Computer Audition.